

Is OpenEvidence Cooked?
What does it mean if general purpose LLMs outperform vertical AI tools

A Mile Wide, A Mile Deep
OpenEvidence has emerged as a poster child for the healthcare industry’s voracious appetite for AI. Two-thirds of US physicians are using the “chatbot for doctors,” traction supporting the Company’s efforts to raise ~$700mm in venture capital dollars, most recently at a $12 billion valuation. An incredible growth story by any measure.
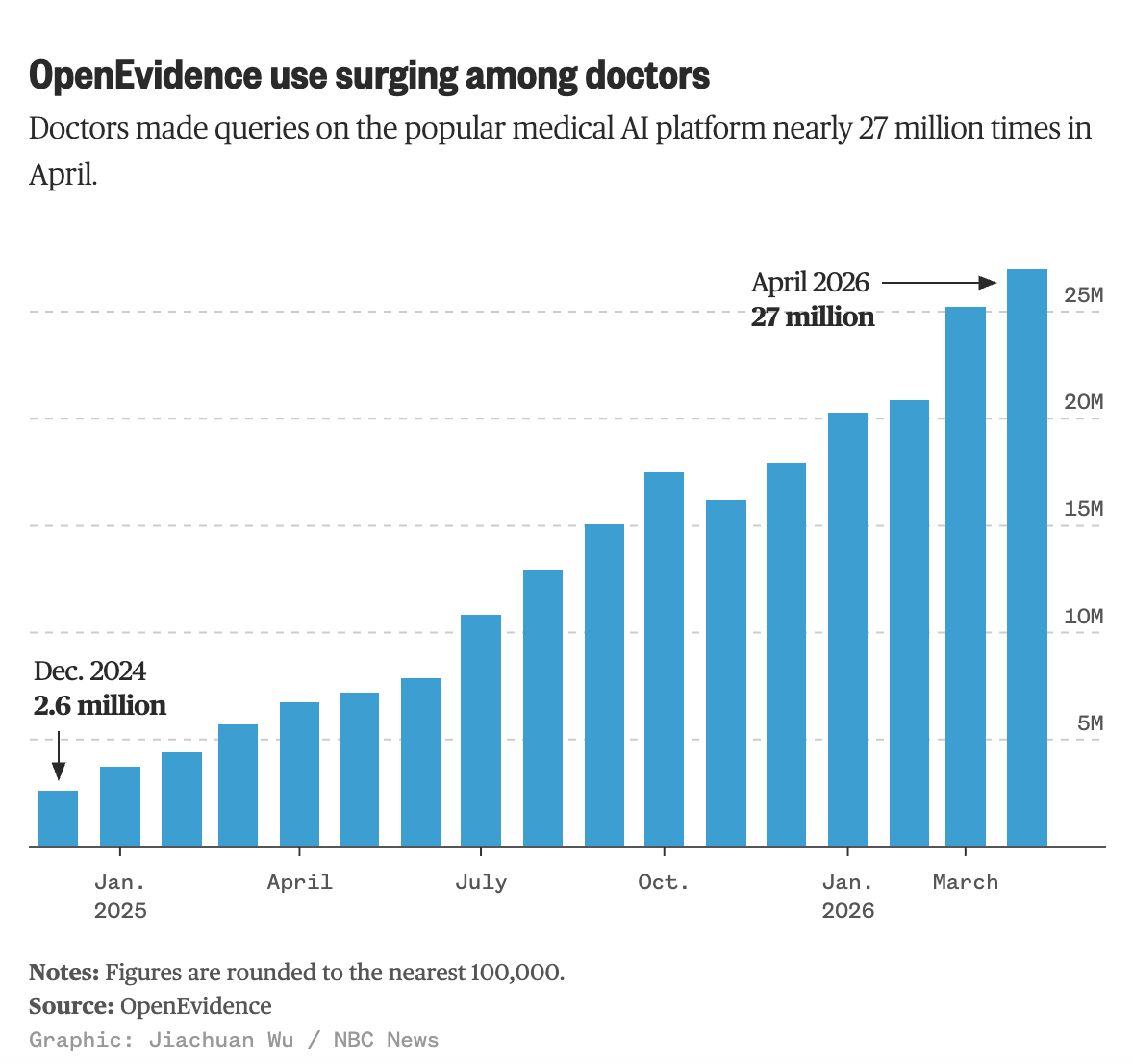
A central premise of OpenEvidence and specialized, vertical AI tools like it is that using curated, mission-specific data should yield more predictable, accurate results with less hallucination.
One of the major weaknesses of most LLMs is the data sets that draw from, typically the entire Internet, with all its useful facts and fallacies. Other companies have recently developed models that draw from far more reliable biomedical data sets… OpenEvidence uses data from a variety of well-respected sources, including peer reviewed medical journal articles.
Source: Mayo Clinic Platform
But a new study from NYU Langone published this week casts doubt on this thesis.
Researchers compared the performance of generalist models from OpenAI, Google, and Anthropic against vertical AI tools from OpenEvidence and UpToDate (Wolters Kluwer). They benchmarked performance multiple ways, the most compelling of which is a blinded panel of clinicians who graded the model outputs against key criteria: clinical correctness, completeness, safety/harm avoidance, and clarity.
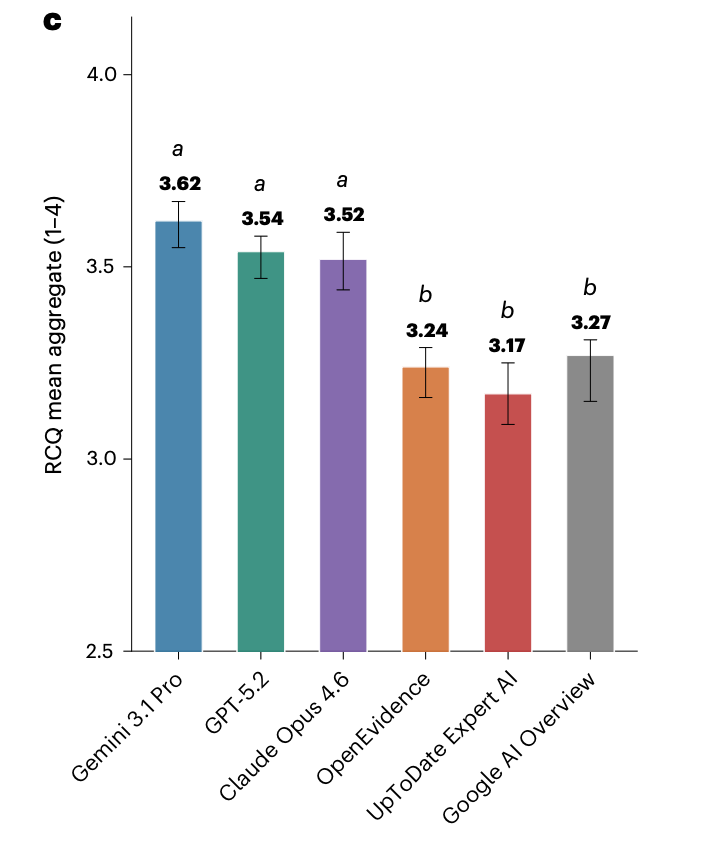
The study found that the generalist models meaningfully outperformed the vertical tools from OpenEvidence and UpToDate across these measures. OpenEvidence, in particular, drew poor grades from the raters.
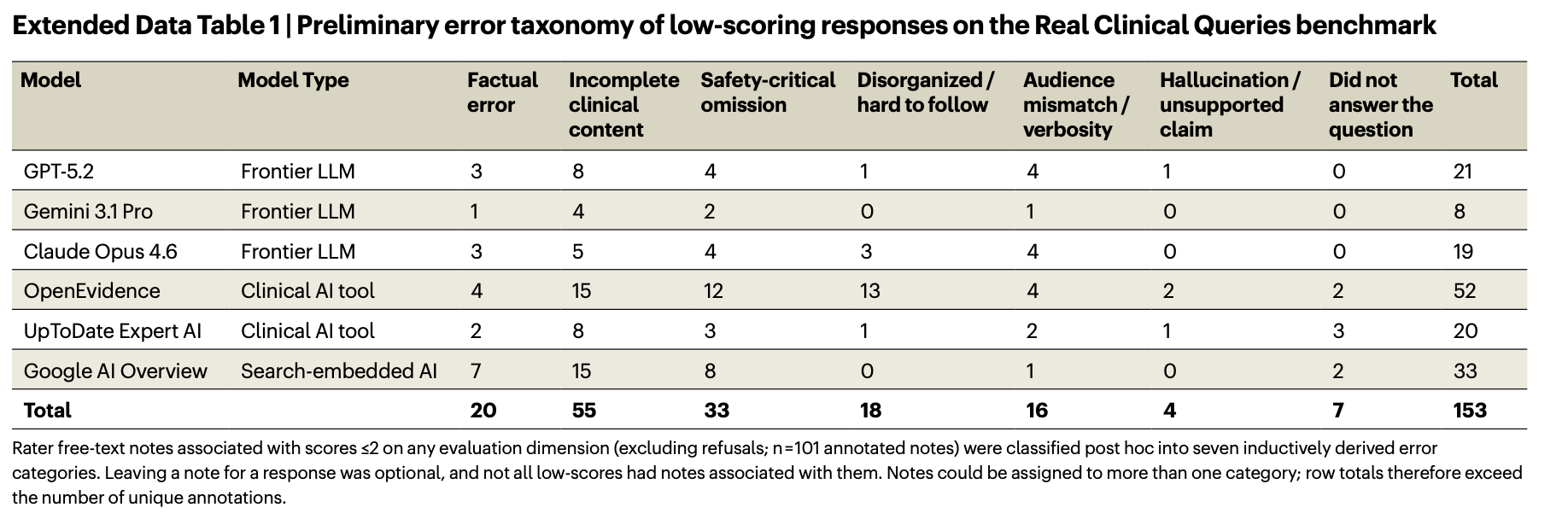
This kind of data further confounds a market narrative that seems to ping-pong weekly between “foundation models are eating the world” and “value will accrue to the application layer.” If vertical tools aren’t reliably and meaningfully better, then it stands to reason that the key competitive flashpoint will be execution. Investors and operators have pointed out that it’s not just output quality, but issues like data usability, compliance, and workflow integration that drive adoption. In a broad oversimplification, both camps appear to have distinct playbooks for digesting this complexity.
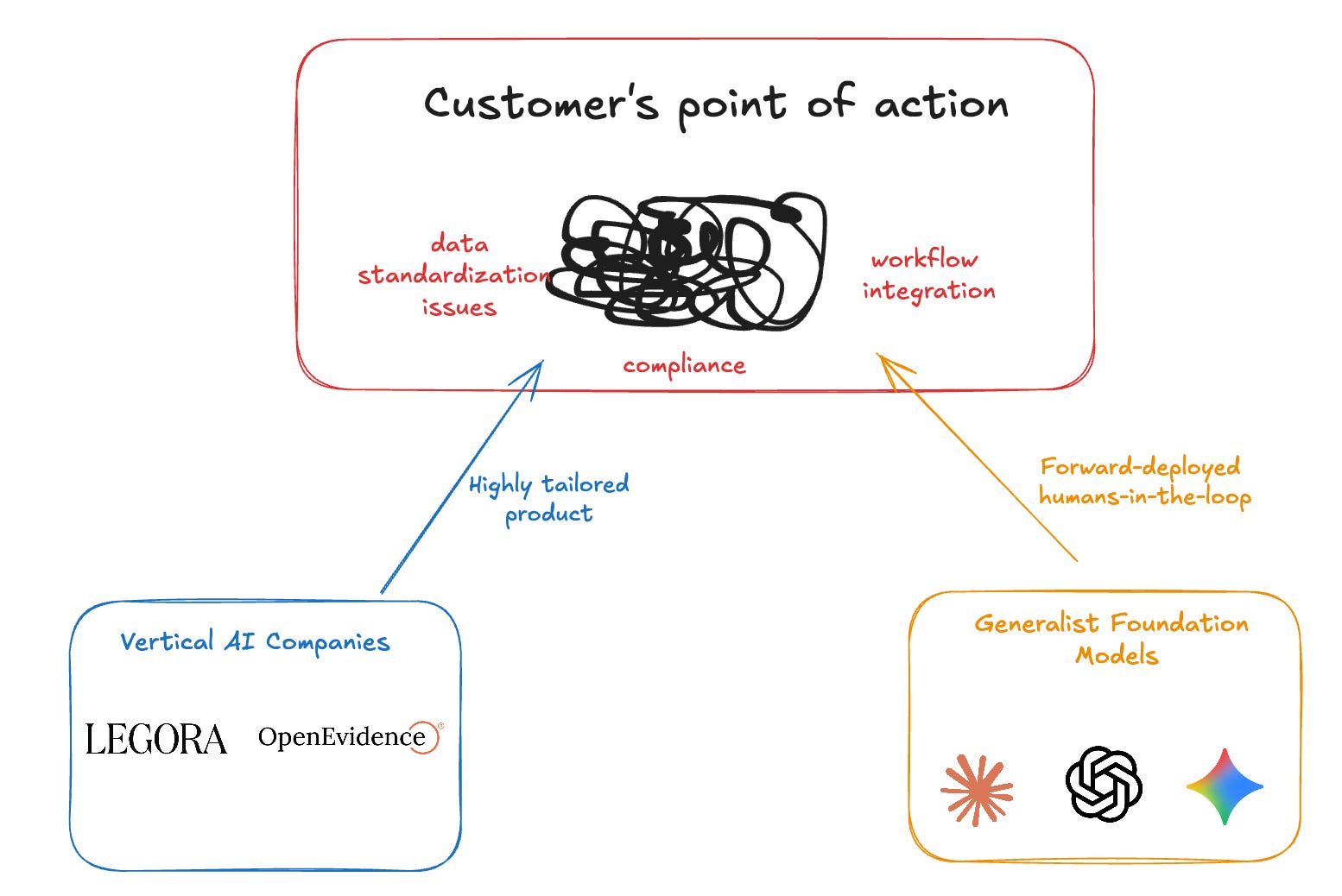
On one hand, vertical AI companies seek to build around customer complexity within the product to drive faster adoption. On the other hand, generalist LLM companies seem to be taking a “forward-deployed” approach, sending “members of the strategy staff” out to resolve customer complexity at the point of action.

My sense is that the playbooks will converge over time.
Vertical AI companies are already adopting more of a forward-deployed posture with their customers.
And foundation model companies are tucking in market-specific products across various disciplines (e.g., Anthropic’s $400mm acquisition of Coefficient Bio, OpenAI’s $100mm acquisition of Torch).
One way or another, human-led domain expertise seems like the critical catalyst for commercial traction.